Both deffered decals and these material decals are unable to render on transparent materials.
These decals are rendered during the seperate translucency pass (same as transparent materials) so there is no way to guarantee the nececary data is available for blending.
Transparent/Additive materials do not write their depth to a buffer, and as such it impossible to reconstruct their worldspace positions.
It might be possible to hack this in very specific situations. Using render targets, you can render a seperate depth buffer in which these objects only render their depth. Then in the decal material, you would use only the smalles depth between pixel depth and this depth buffer.
It’s funny to me no one posted the result of what you said. Derivatives of WPBT function look pretty cool when fed into Tobasco’s idea. I wish I could mix it with some kind of self shadowing. I like the effect on high detail / displacment-ed geometry. Although, I wonder if we get the same effect using just a spotlight.
Is it possible to change the axis from which to blend, currently its the up, or Z axis. Is it possible to rotate the object and have it project the texture on a vertical surface, and not to have stretching on a horizontal one?
first of all thanks for this amazing tutorial .
i might be a bit late but do you know how to exclude certain meshes from being projeced ?
ty in advance
You’ll need a screenspace buffer (depth/presorted stencil) to check against. with presorted, I mean a stencil that only draws if it is not obstructed by the z-buffer
In personal projects I usually use the custom depth buffer.
If it is not a personal project, now is the time to go and talk to your friendly neigbourhood graphics programmer and explain the situation. They’ll be able to help you out.
Once you have that.
In case of stencil, just use the stencil as a mask (multiply before feeding into opacity)
In case of depth buffer, use saturate(sceneDepth- depthBuffer) to only show where the projected pixels would be in front of the recorded depth buffer. (otherwise if the selected object is obscured, it will still be able to mask out pixels)
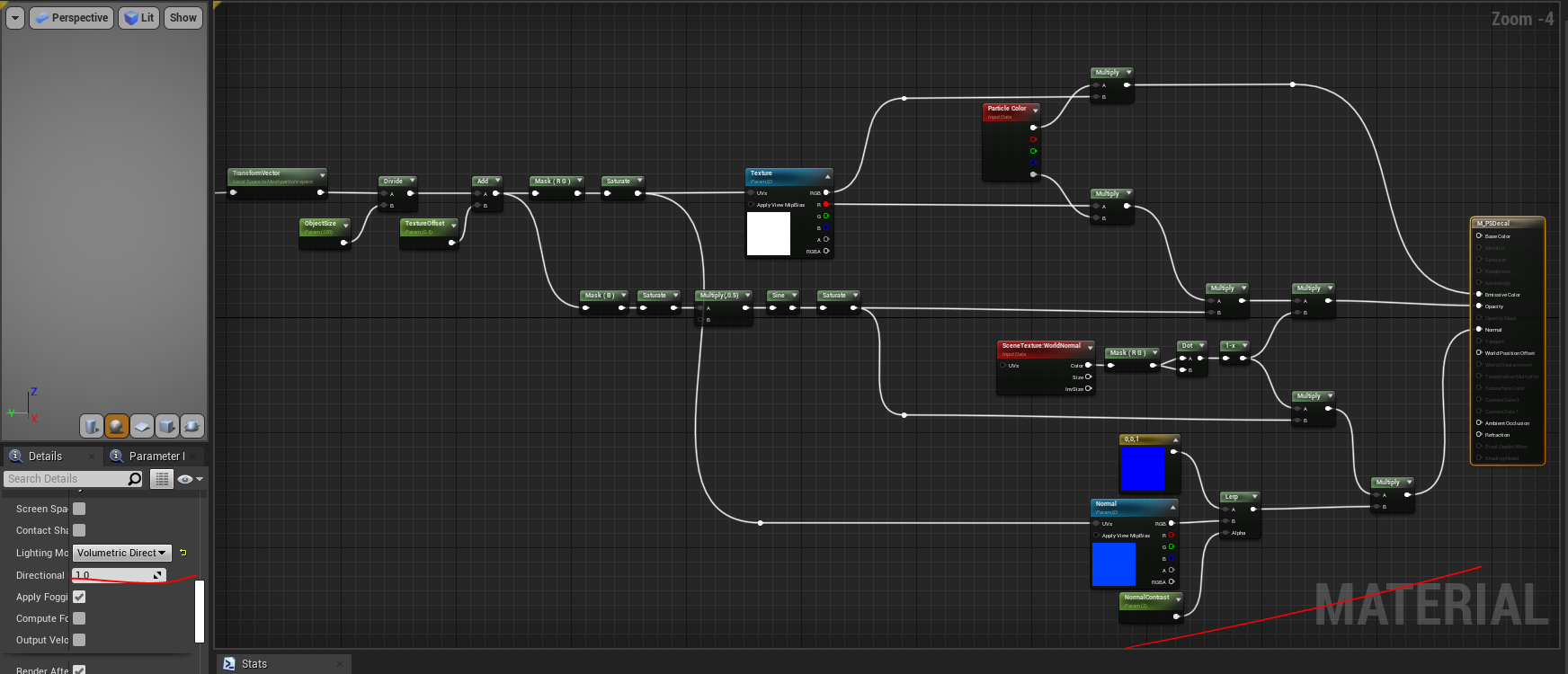
This is really an awesome guide. Can you cover me on this node tho “WorldPositionBehindTranslucency”? I kinda understand the later part but what does this node do?
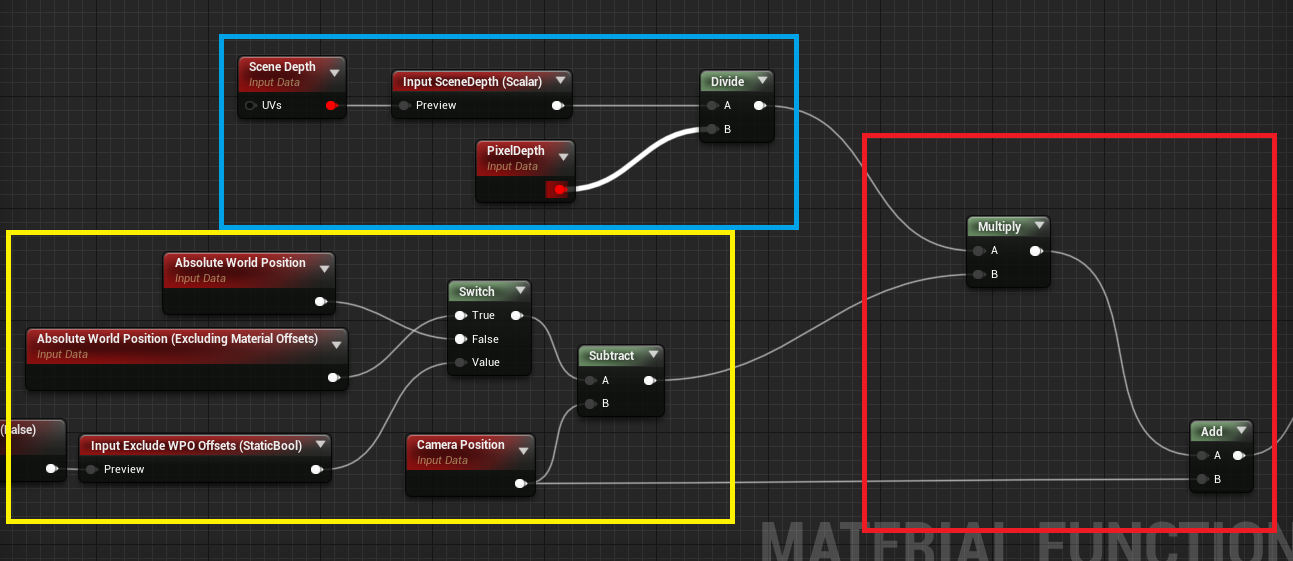
Scene Depth is the depth recorded in the depth buffer (translucency doesn’t write into depth, so we can be certain this is the closest opaque object)
Pixel Depth is the depth of the current pixel
Dividing SceneDepth by pixeldepth, or essentially, what part of the total scenedepth is our current pixeldepth
Yellow:
Absolute world position is the current pixel in world space.
CamerPosition is the camera position in world space.
Subtracting Camera position from the world position gives us a vector pointing from the camera to the pixel we currently deal with (fragment technically I believe, but it’s ok to think about it as pixels)
Red:
First we multiply our vector from the camera to the pixel position with the scene depth fraction, so now we have a vector which points from the camera in the direction of the current pixel, but with the length of the scene depth.
So now the only thing we need to get a worldspace vector is to add our camera position back into the vector.
To visualize the depth situation, it can be useful to think in numbers.
Current scenedepth is 10m
Current pixeldepth is 5m ( it’s always smaller, if it were bigger the pixel would be behind the depth end therefore not get rendered)
Fraction = 10/5, or we need to make the vector 2 times as large to reach the current scene depth.
Yes. First, thanks for spending your time explaining things to me. Tbh it was still confusing me at first and I had to spend all day to research scene depth and pixel depth since I rarely use both when I make material. But now, it’s getting more and more clear to me, I’m very grateful and thank you for sharing your knowledge to our community. I started learning VFX by myself so it’s really difficult.
Hope you have a nice day!
I don’t really understand what you are tying to do.
If you want the fade the decal based on the normal of the background, have a look at the post from Shannon Berke (Reply 10)
There is a good explanation of how to use the world normal scenetexture to your advantage!
Work super well with collision, there is some artifact if multiple decal is spawned at same position.
Is there any ways to kill particle on first collision inside niagara ?
and
Is there an option to disable homegrid as deflector? ( Just wonder what if I have object that below homegrid)
I believe it’s not part of the module, but you can set aging on collision, so if you set a really large number there, it looks the same as killing on hit.
What is homegrid? You can set a tracing channel and then remove that object from that channel to stop colliding with it.